It all started when I wanted to analyze some MeP code. Usually, I do all my disassembly in IDA Pro, but this is one of the few processors that isn’t supported by IDA. Luckily, there is objdump for this obscure architecture. After fumbling around for a bit, I was convinced that porting the disassembler to IDA would be a much better use of my time than manually drawing arrows and annotating the objdump output.
Process
Turns out, there isn’t too many resources online on writing IDA processor modules. The readme of the SDK was minimal (it tells you to read the sample code and the header files) and refers to two documents: an online guide that is now gone and The IDA Pro Book by Chris Eagle. Opening the book to the chapter on writing processor modules, you’re greeted with a dire warning to turn back (along with a note about the lack of documentation) as many have tried and failed.
One of the reasons why writing a processor module is so challenging is that the processor_t struct contains 56 fields that must be initialized, and 26 of those fields are function pointers, while 1 of the fields is a pointer to an array of one or more struct pointers that each point to a different type of struct (asm_t) that contains 59 fields requiring initialization. Easy enough, right?
Chris Eagle, The IDA Book 2nd Edition
Well, I’m not easily discouraged, so I read on and familiarized myself with the process of creating a processor module. I’m not going to describe the process here in detail because Chris does a great job in the book, but I’ll give a brief outline
IDA Processor Module
There are four components of a processor module. The “analyzer” parses the raw bits of the machine code and generates the information about an instruction. The “emulator” uses that information to help IDA with further analysis. For example, if an instruction references data, your module can tell IDA to look for data at that address. If the instruction performs a function call, your module can tell IDA to create a function there. Contrary to its name, it does not actually “emulate” the instruction set. The “outputter” does just that: given the data generated from the analyzer, it prints out the disassembly to the user. Finally, there’s the architectural information, which is not a component mentioned elsewhere but I consider it one. This is not code, but static structures that tell IDA information such as the names of the registers, the mnemonic of the instructions, alignments and so on.
CGEN
The binutils (objdump) for MeP are machine generated by CGEN. CGEN attempts to abstract away the task of writing CPU tools (assemblers, disassemblers, simulators, etc) into writing CPU definitions. The definitions describe the CPU (including the hardware elements, the instruction sets, operands, etc) with the Scheme language. CGEN takes the definition and outputs C/C++ code for all the needed CPU tools. Originally I wanted to avoid CGEN and just wrap the (generated) binutils code to an IDA module (à la Hexagon). In theory, your module does not have to follow the convention laid out above. You can make the analyzer record the raw bits, the emulator do nothing, and the outputter use binutils to generate a complete line and print it out. However, in doing so, you essentially lose most of the power of IDA (finding xrefs, stack variables, etc). It would also be a shame to not use all the information given to us by the CGEN CPU definitions. These definitions (in theory) are strong enough to generate RTL code to implement the processor, so we would like to give as much of this information to IDA as possible.
CGEN Generators
The generators themselves (CGEN docs refer to them as “applications”) are also written in Scheme, in the Guile dialect. I have never written a line of functional code before, so it took me a day to understand the relatively small codebase. CGEN has its own object system that they call COS. Everything defined in the CPU descriptions becomes objects, and each generator gives these objects methods to print themselves out. For example: the simulator might give the operand object a “generate code to get value” method. Then a call to generate the semantics of an instruction into C code would use these objects’ methods. Like a true software engineer, I cut out functions from the generators for the simulator, disassembler, and architecture description and stitched them together with my own code to generate various components of an IDA module.
The analyzer used, as its base, the simulator instruction decode generator. I had to modify CGEN to record the order of operands as specified by the instruction syntax (the only modification to CGEN itself, everything else are additions). Then, I overwrote the simulator’s method definitions for extracting the operands from the instruction with code to populate the “cmd” structure in IDA (which requires the operands to be ordered).
The emulator used the simulator model generator as its base and was the most difficult to write (in terms of code complexity). The one major issue here is that while the generated simulator expects code to run in order and have state information stored, the IDA emulator does not store state information and IDA does not guarantee that your emulator will be called in the order that the instructions appear. That means we cannot make any assumptions about the state and our emulator can only make decisions based on the instruction alone. Because we only care about finding data and code references with the emulator, we can make the following simplifications:
-
Any conditionals will have the condition stripped out and all paths will be taken
-
Using any values from registers will stop the emulator and return immediately
-
Setting any values to registers will evaluate the value but discard the result
The first point allows for xrefs to be found regardless of the condition. A conditional branch, for example, will allow for a code xref to be generated. The second point is there because we do not know the state, so any dependencies on a register value that’s not already stripped out will make finding a xref difficult. In theory, we can still find offset xrefs this way, but we would have to know that only additions/subtractions are used and only a single register is used and that adds a lot of complexity. The third point allows memory reads to be captured. With those simplifications in place, we know that any memory reads/writes and any PC reads/writes that are found without knowing the state can be turned into xrefs.
The outputter used the syntax parser (binutils’ opcode builder) as its base. It reads the instruction definition in order to output the right orderings of parenthesis, commas, and so on. I just replaced the generate print methods of the hardware objects to generate calls to IDA output functions.
Results
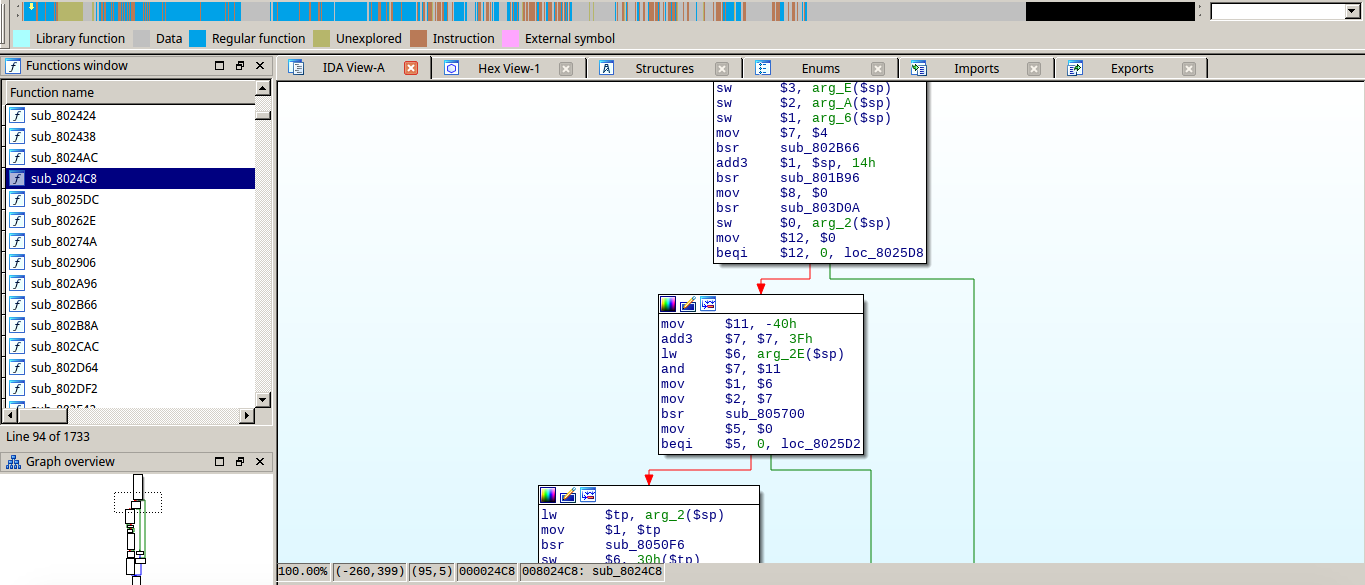 MeP executable loaded and recognized by IDA Pro. All the blue is a result of the auto-analysis.
MeP executable loaded and recognized by IDA Pro. All the blue is a result of the auto-analysis.
At the most basic level, the generated modules outputs what you would expect from objdump. The analyzer will find the right type for the operands (if possible). The emulator tries to find all constant addresses and adds xrefs to them (code and data). The outputter will print all instructions correctly, and the operands with the right type/size/name if needed.
The main thing it doesn’t do right now is keeping track of the stack pointer. It also does not identify if branches are jumps or calls (requiring CF_CALL flag). It does not identify if an instruction does not continue flow (requiring the CF_STOP flag) (it’s actually trivial to add this, but harder to add it without introducing emulator code to other generators. Since it’s easy to identify the instructions by hand, I decided to leave it out).
Usage
Once you generate the IDA module components, you still need to manually write the processor_t structure, the notify() function (optional), and implement and special print functions (as defined by the CPU definition). Then you can copy the CGEN headers from binutils and compile it with the IDA SDK. Take a look at the MeP module as an example. You can reuse most of the non-generated code as-is (just change some strings and constants). If you run into any issues, feel free to contact me. I haven’t tested this on anything other than MeP because of laziness but I hope the code works more generally.
Downloads
The CGEN code is here and the Toshiba MeP module is here. The MeP module has basic stack tracking and call recognition added manually. When I have the time, I’ll port the rest of the CGEN supported modules that IDA does not support over.
看看!
[…] * 原文链接:yifan.lu,转载请注明来自FreeBuf黑客与极客(FreeBuf.COM) […]